{kind=link}

Reinforcement Learning
December 10, 2023Machine learning은 크게
- supervised learning
- unsupervised learning
- reinforcement learning
의 세 가지 패러다임으로 분류된다.
supervised learning은 label이 붙은 데이터가 필요하고, unsupervised learning은 label이 필요 없고 generative 모델 형태로 발전하고 있다.
reinforcement learning은 input에서 output으로 연결되는 function을 학습하는 것이 아닌, input에서부터 최종 목표를 이루기위해 수행할 전략을 학습하는데 집중한다. 체스 게임에서 게임을 이기기 위해 다음 수를 결정하는 것과 구글의 DeepMind가 만든 AlphaGo가 대표적인 reinforcement learning의 예시이다.
Reinforcement Learning 강화학습
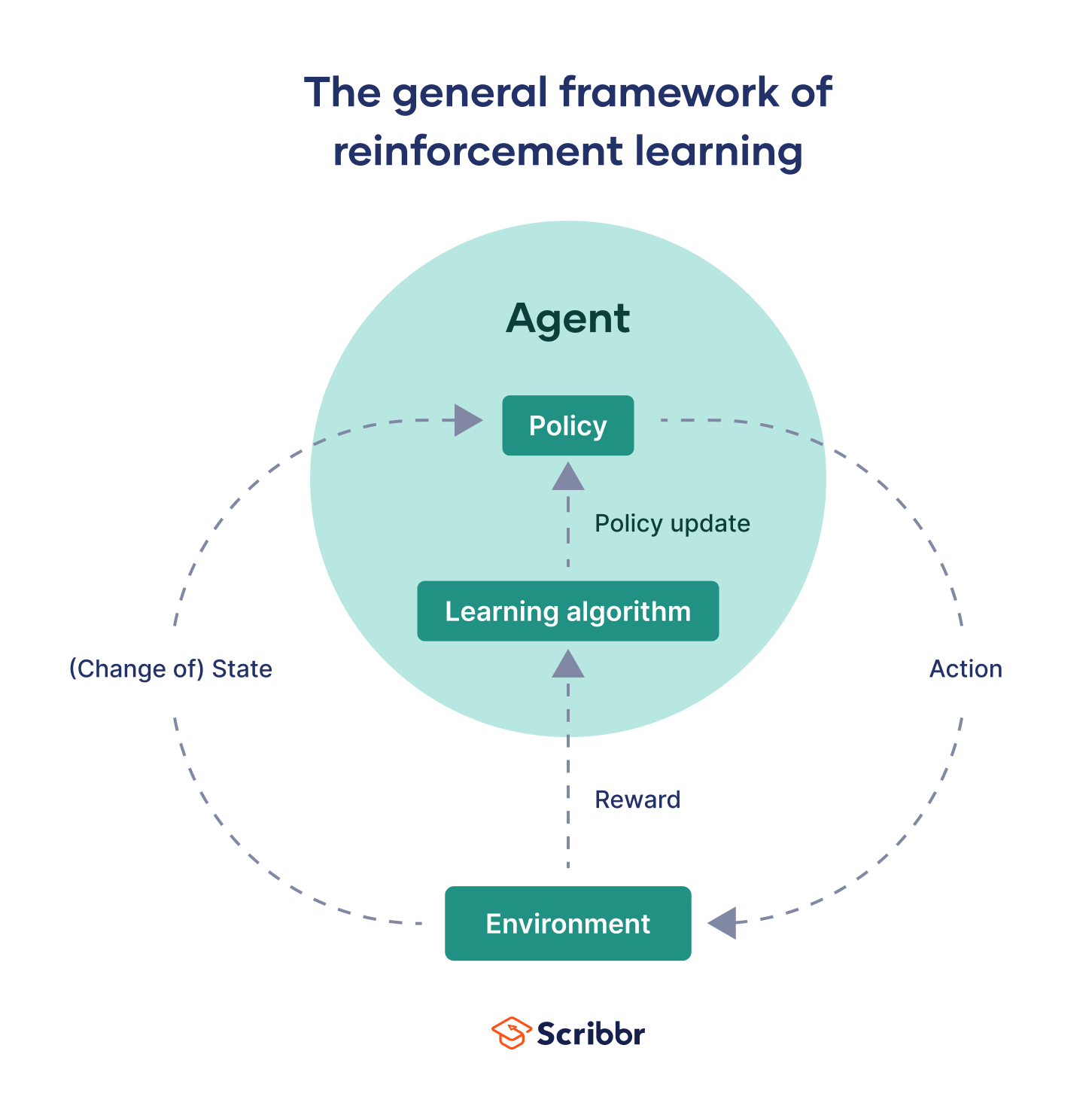
RL에서 Agent는 제공된 Environment(환경)에서 결정하는 법을 학습하고 그 결정에 따라 Action(행동)을 취한다.
RL에서는 Agent의 모든 행동 하나하나마다 피드백을 받지 않는 대신, agent는 행동에 따라 State(상태)를 갖는다. Agent의 초기 상태 $s_0$에서 Agent가 $a_0$라는 행동을 하면 Agent의 상태가 $s_0$에서 $s_1$으로 transition(전이)되며, 그 후 Agent는 다른 행동 $a_1$을 하는 식으로 Cycle이 이뤄진다.
Agent는 State에 따라 Reward(보상)을 받기도 한다. Agent의 일련의 Action과 State를 Trajectory(궤적)라고 하는데, Agent가 State $s_2$에서 Reward를 받았다면, 이 Reward를 받게 된 Trajectory는 $s_0, a_0, s_1, a_1, s_2$가 된다.
이 Reward에 기반해 Agent는 장기적으로 받을 Reward를 최대화도록, 주어진 State를 기반으로 어떤 Action을 행하도록 최적의 전략을 학습한다. 이렇게 학습한 전략을 Agent의 Policy(정책)이라고 한다. Policy는 State와 Reward로 표현된 Action의 모음이다.
RL의 최종 목표는 Agent가 자신이 처한 State에서 최대의 Reward를 받을 수 있게 Policy를 Update 하는 것이다.
Agent가 initial state에서 final state에 이르기까지 environment와 interactions한 play를 Episode라고 한다.
Reinforcement Learning Algorithms 강화학습 알고리즘 유형
Agent는 RL 모델을 통해서 policy를 학습한다. RL 모델은 사전에 정의된 알고리즘을 기반으로 작동하는데, 크게 두 분류로 나눌 수 있다.
- Model-Based 모델 기반
- Model-Free 모델 프리
Model-Based
Model-Based는 Agent가 모델의 편향된 표현을 학습하고 실제 환경에서 제대로 수행하지 못할 가능성이 높아 RL 시스템을 구현할 때 자주 사용되지 않는다. 여기서 모델은 environment의 모델인데, 이는 reward와 environment 내에서 state transition을 추정하기 위해 사용될 수 있는 함수의 수학 공식을 말한다.
Model-Free
Model-Free 방식은 environment 모델 없이 작동하며 현재 RL 연구 개발에 일반적으로 사용된다.
Model-Free RL에서 Agent를 훈련시키는 방법에는 주로 두 가지가 있다.
- Policy Optimization
- Q-Learning
Policy Optimization
Policy Optimization 방식에서는 policy를 다음과 같이 현 state와 action의 함수 형태로 정의한다.
| $Policy = F_\beta(a | S)$ |
$\beta$는 함수의 내부 매개변수이며, gradient ascent를 통해 policy 함수를 최적화하도록 업데이트된다.
Policy Optimization 기반 RL 알고리즘의 예로는 다음과 같은 것들이 있다.
- Policy Gradient
- Actor-Critic
- Trust Region Policy Optimization, TRPO
- Proximal Policy Optimization, PPO
Policy Optimization 함수는 직접 policy를 최적화하므로 알고리즘이 매우 직관적이다. 그러나 이 알고리즘은 대부분 policy를 기반으로 하므로 policy가 업데이트 되고 나면 각 step마다 데이터를 다시 샘플링 해야한다.
Q-Learning
Q-Learning은 policy optimization 알고리즘과 달리, value 함수를 기반으로 value 함수를 최적화한다.
Value 함수는 Agent의 현재 state에 대해, agent가 현재 episode 끝에 받게 될 reward의 총합에 대한 기대치를 출력한다.
Q-Learning에서는 현재 state와 action에 모두 영향을 받는 value 함수 중 하나인 action-value(행동-가치) 함수를 최적화한다. Action-value 함수는 상태 $s$에서 agent가 행동 $a$를 취함으로써 얻게 될 long term reward(episode가 끝날 때 까지 받게 될 reward)를 구한다.
Action-value 함수는 일반적으로 $Q(S,a)$로 표현되며, Q-함수라고도 한다. Action-value는 $Q$-값이라고도 한다.
모든 $(S, a)$ 쌍에 대한 $Q$-값은 2차원 테이블에 저장할 수 있다. Q-Learning의 목표는 이 Q-값 테이블을 만드는 것이다. 테이블이 만들어지면 agent는 주어진 state에서 가능한 모든 action에 대한 Q-값을 조회하고 Q-값이 최대인 action을 하면 된다.
Q-값은 Bellman Equation(벨만 방정식)을 통해 얻을 수 있다. 공식은 다음과 같다.
$Q(S_t, a_t) = R + r*Q(S_{t+1},a_{t+1})$
벨만 방정식은 Q-값을 재귀적으로 계산하는 방식이다. $R$은 상태 $S_t$에서 행동 $a_t$를 취함으로써 얻는 reward이고 $r$는할인 계수로, 0과 1 사이의 스칼라 값이다. 할인 계수는 즉각적인 reward와 long term reward에 가중치를 얼마나 부여할지 정의한다.
Deep Q-Network(DQN)
Q-Learning은 Q-값 테이블을 만드는 것이 핵심이다. 하지만, 비디오 게임과 같이 state가 Q-값 테이블로 관리할 수준을 넘어설 만큼 많은 state가 있을 경우 메모리 부족의 문제로 실행할 수 없다.
DQN은 주어진 state-action 쌍에 대해 Q-값을 출력하는 DNN(Deep Neural Network)를 사용한다. DNN은 input 각각에 대해 스칼라 값인 Q-값을 출력한다.
DNN은 항상 iid(independent and identically distributed, 독립 항등 분포) 데이터 샘플로 작업해왔는데, RL에서는 현재의 output이 모두 다음 input에 영향을 미친다. 예를 들어 Q-러닝의 경우, Q-값이 다른 Q-값에 종속된다.
이는 우리가 끊임없이 움직이는 target으로 작업하고, input과 target 사이에 높은 상관 관계가 있음을 의미한다. 이는 훈련 과정의 불안정성을 초래한다.
DQN은 다음 2개의 특징으로 이 문제를 해결한다
2개의 분리된 DNN 사용
DQN은 main DNN과 target DNN으로 분리된 2 개의 네트워크를 사용한다. 두 DNN은 동일한 architecture를 갖는다.
Main DNN은 현재 state-action 쌍의 Q-값을 계산하고, target DNN은 다음(target) state-action 쌍의 Q-값을 계산하는데 사용된다.
Main DNN의 가중치는 매 학습마다 update되지만, target DNN의 가중치는 고정된다. Gradient Descent가 K번 반복될 때마다 main DNN의 가중치를 target DNN에 복사한다.
이러한 방식은 훈련 과정을 상대적으로 안정적으로 유지하고, 가중치를 복사하는 방식은 target DNN의 예측 정확도를 보장한다.
Experience Replay Buffer 경험 재현 버퍼
DNN은 input으로 iid 데이터를 기대한다. 그러므로 trajectory를 buffer에 저장한 다음, buffer에서 데이터 batch를 random sampling하여, 이 mini-batch를 DNN의 input으로 넣어준다.
이 Batch는 random sampling된 데이터로 구성되므로 분포가 iid 데이터 샘플의 분포와 비슷해보이므로, DNN 훈련 과정을 안정화하는데 도움이 된다.
# concepts