
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
- Link : https://arxiv.org/abs/1511.06434
ABSTRACT
이 논문에서는 Deep Convolutional Generative Adversarial Networks(DCGAN)를 소개한다. DCGAN의 generator와 discriminator의 두 가지 신경망이 서로 경쟁하면서, 각각의 신경망은 객체의 부분부터 장면 전체에 이르기까지의 다양한 표현 계층 구조를 학습한다. Generator와 discriminator는 객체의 세부적인 부분(손, 발, 얼굴 등)부터 전체적인 장면(전체 얼굴, 전체 물체)까지 다양한 수준의 정보를 학습한다. Generator는 더 진짜같은 이미지를 만들기 위해 다양한 수준의 표현을 이해해야 하고, discriminator는 이를 판별하기 위해 같은 표현 계층 구조를 인지해야 한다. 추가로, 학습한 features를 이용해 다양한 이미지 관련 문제에 적용 가능함(General image representations)을 보여준다.
1 INTRODUCTION
Image representations를 build하는 좋은 방법 중 하나는 GAN을 이용하는 것이다. GAN은 maximum likelihood techniques를 대체할 좋은 대안이며, GAN의 learning process와 lack of heuristic cost function은 representation learning을 위한 매력적인 특징이다. 하지만 GANs 모델들의 학습은 불안정한 것으로 알려져있고, 때때로 알 수 없는 결과를 만들어내기도 한다.
본 논문에서는 다음과 같이 4가지의 기여(Contributions)을 한다.
- 대부분의 환경에서 안정적인 학습이 가능한 Convolutional GANs, Deep Convolutional GANs(DCGAN)의 구조를 제안한다.
- 학습된 discriminators를 이용하여, image classification tasks에서 다른 unsupervised algorithms보다 경쟁력있는 성능을 보인다.
- GAN의 학습된 filter를 시각화하여, 특정 filter가 특정 object를 그리도록 학습됨을 경험적으로 보여준다.
- Generator가 생성된 이미지 샘플들의 의미있는 특성(색상, 형태, 표정 등)을 쉽게 조작할 수 있게 하는 벡터 산술(vector arithmetic) 속성이 있음을 보인다.
3 APPROACH AND MODEL ARCHITECTURE
지금껏 CNN을 이용하여 GANs를 scale up하려는 시도는 성공적이지 못했다.
본 논문에서는 많은 모델들을 탐색해본 끝에, 다양한 데이터셋, 고해상도 학습, 더 깊은 generative models에 대해 안정적인 훈련이 가능한 구조들을 확인했다.
접근 방법의 핵심은 최근에 증명된 CNN 구조를 바꾸는 세가지 방법을 적용하고 수정하는 것이다.
먼저, maxpooling과 같은 pooling functions를 strided convolutions로 대체하여 신경망이 스스로 spatial downsampling을 학습하도록 한다. Discriminators는 strided convolutions를, generator는 fractional-strided convolutions를 사용한다.
두 번째, CNN의 마지막 layer인 Fully Connected Layer 대신 global average pooling을 사용하여 stability를 증가시켰다.
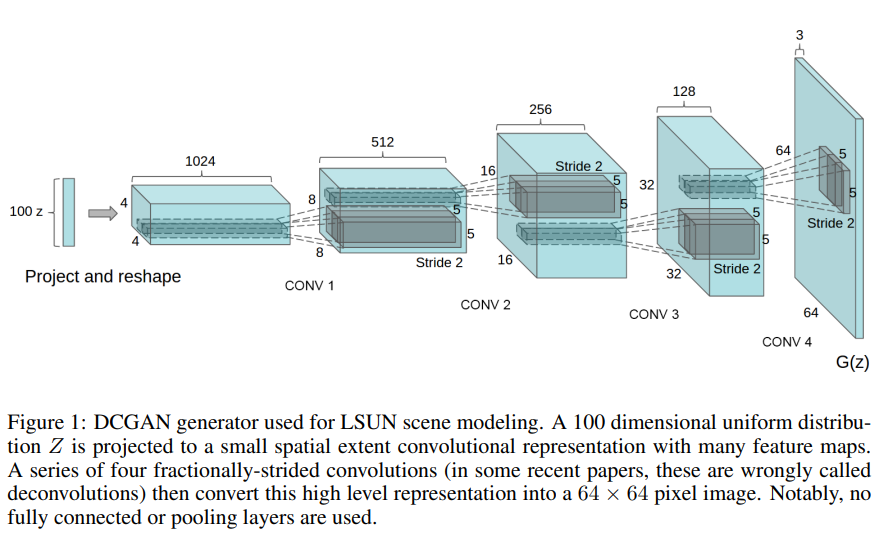
세 번째, Batch Normalization을 사용하는 것이다. Batch Normalization은 input을 zero mean과 unit variance를 가지도록 정규화하여 학습을 안정화시킬 뿐만 아니라 모델의 빈약한 initialization 문제를 다루는 데에 도움을 주고 deeper 모델에서의 gradient flow에 도움을 준다. 모든 layer에 batchnorm을 적용하면 모델이 오히려 불안정해지기에, generator의 output layer와 discriminator의 input layer를 제외한 layer에 batchnorm을 적용한다.
추가로, generator의 모든 layer에 ReLU activation을 사용한다. 다만, output layer는 Tanh을 사용한다. Discriminator에서는 모든 layer에 LeakyReLU activation을 사용한다.
4 DETAILS OF ADVERSARIAL TRAINING
LSUN, Imagenet-1k, Faces dataset에 대해 학습을 진행하였고, 다음과 같은 디테일이 사용되었다.
- No pre-processing
- 모든 모델들은 mini-batch SGD로 학습되었고, mini-batch 사이즈는 128이다.
- 모든 가중치들은 zero-centered Normal distribution with standard deviation 0.02로 초기화하였다.
- LeakyReLU는 slope of the leak을 0.2로 설정하였다.
- 이전 GAN은 accelerate training을 위해 momentum을 사용했지만, 여기서는 Adam optimizer를 사용한다. Learning rate는 0.001은 너무 높다고 생각해 0.0002를 사용했다. 추가로 momentum term $\beta_1$로 0.9를 사용하면 신경망이 안정적으로 수렴하지 않고, 훈련 과정에서 성능이 계속해서 변화하거나 불안정해져서(training oscillation and instability) 모델의 안정성을 위해 값을 0.5로 줄였다.
5 EMPIRICAL VALIDATION OF DCGANs CAPABILITIES
DCGAN의 discriminator를 supervised tasks에서 feature extractor로 사용하였을 때 좋은 성능을 보였다.
6 INVESTIGATING AND VISUALIZING THE INTERNALS OF THE NETWORKS
6.1 WALKING IN THE LATENT SPACE
Latent 변수 $z$에 대해 이미지에서 semantic한 변화가 일어나는 지를 확인한다. 만약 $z$에 변화에 따라 결과가 갑작스럽게 바뀌는 것은 모델이 이미지의 특징을 제대로 학습한 것이 아닌, 이미지를 외웠다는 뜻이 된다. 이미지를 외웠다는 것(Memorization)은 모델이 overfitting 되어 training data와 latent 변수 $z$를 1:1 매핑했다는 의미이다. 따라서 $z$의 변화에 따라 일부 물체가 생기거나 없어지는 의미있는 변화가 부드럽게 나타남을 보이는 것이 generator 모델 연구의 핵심이다.

왼쪽열에서 오른쪽열로 $z$값이 부드럽게 변화함에 따라 6번째 행에서 점점 더 큰 창문이 방에 생기는 것과 10번째 행에서 TV가 점차 창문으로 바뀌는 것을 볼 수 있다.
6.2 VISUALIZING THE DISCRIMINATOR FEATURES
이전의 연구들에서 large image datasets으로 학습한 supervised CNN은 이미지의 특성을 아주 잘 학습하는 것으로 보였고, scene classification에서 학습한 supervised CNN은 object detectors로서 학습되는 것을 보였다. 여기서는 large image dataset에서 학습한 unsupervised DCGAN도 표현 계층 구조를 학습할 수 있음을 보인다.

Springenberg et al., 2014가 제안한 guided backpropagation을 통해 LSUN 데이터셋에서 학습된 discriminator의 filters가 침대나 창문과 같은 침실의 특징들을 activate하는 것을 볼 수 있다.
6.3 MANIPULATING THE GENERATOR REPRESENTATION
6.3.1 FORGETTING TO DRAW CERTAIN OBJECTS
Generator가 침대, 창문, 램프, 문 그 외 잡다한 가구들의 표현을 학습한다는 것을 sample들을 통해 알 수 있는데, 이런 표현들이 어떤 형식으로 학습되는지 창문의 요소를 제거하여 학습 시켜보기로 했다.

“Window” filters가 제거된 모델로 이미지를 생성하였더니 창문이 있던 곳이 문이나 거울로 변화한 것을 볼 수 있다. 퀄리티는 조금 떨어져도 구성요소는 전과 비슷한 것을 볼 수 있다.
6.3.2 VECTOR ARITHMETIC ON FACE SAMPLES
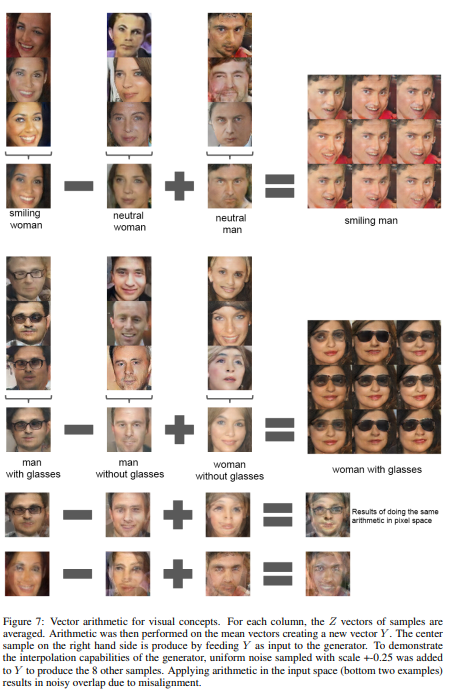
Word2Vec에서 Vector(”King”) - Vector(”Man”) + Vector(”Woman”) = Vector(”Queen”)이 성립함을 보였는데, 이런 vector arithmetic이 generator에서도 가능함을 보였다.
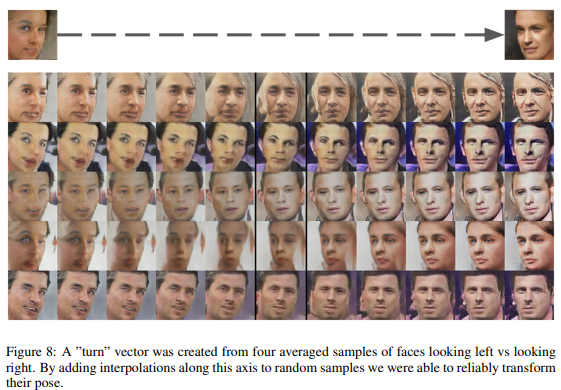
또한, 얼굴의 포즈(오른쪽을 바라보고 있는 포즈, 왼쪽을 바라보고 있는 포즈)도 $z$ space에서 선형적으로 모델링되었음을 볼 수 있다.
7 CONCLUSION AND FUTURE WORK
본 논문에서는 GAN 학습을 위한 보다 안정적인 구조의 DCGAN을 제안하면서, Adversarial Networks가 supervised learning과 generative modeling을 위한 이미지 표현 학습에 좋다는 사실을 보였다. 그렇지만 아직, 모델의 불안정성 문제(학습이 길어질 때 filter의 일부가 무너지는 문제)가 남아 있으며, 이에 대해 추후 연구가 필요함을 밝혔다.
Leave a comment