
Improving Language Understanding by Generative Pre-Training
Improving Language Understanding by Generative Pre-Training
- Link : https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
Abstract
자연어를 이해하는 것은 textual entailment, question answering(질의응답), semantic similarity assessment(의미 유사도 평가), document classification(문서 분류)와 같은 여러 task를 포함한다.
하지만, unlabeled된 데이터는 충분해도, 특정 task를 위한 labeled 데이터가 부족하여 판별 모델을 충분히 학습하기에는 어려움이 있다. 가령 인터넷 기사들은 많지만, 인터넷 기사들을 주제별로 분류한 데이터를 찾기는 쉽지 않아, 인터넷 기사를 주제별로 분류하는 모델을 학습하기에 어려움을 겪는다.
이 연구에서는 언어 모델을 unlabeled text를 이용해 generative pre-training한 후, 각 task에 맞게 discriminative fine-tuning을 하는 방식을 통해 여러 task에서 큰 성과를 낼 수 있음을 보인다
즉, NLP 안에서의 여러 세부 task들, 예를 들어 의미 유사도를 평가하는 task만을 위한 모델을 만드는 것보다 다양한 text 데이터들을 가지고 모델을 학습한 후, 세부 task에 맞게 fine-tuning을 거쳐 더 좋은 성능을 보일 수 있다는 것을 보인다.
Large Language Model의 시초 GPT-1에 관한 논문이다.
1. Introduction
NLP에서 raw text로부터 효과적으로 학습하는 능력은, supervised learning의 의존도를 낮출 수 있기에 핵심 능력이라 할 수 있다.
대부분의 deep leaerning 방식은 labeled된 데이터가 상당히 필요한데, 현실에서는 labeled된 데이터들이 부족하기에 모델을 다른 도메인에 적용하기에는 제약이 생긴다.
만약, 모델이 unlabeled 데이터의 언어 정보를 활용할 수 있다면, 시간과 비용을 잡아먹는 데이터의 label을 획득하는 방법의 대안이 될 수 있다.
또한 supervision이 가능한 경우에도, unsupervised 방식으로 좋은 representation을 학습하는 것은 상당한 성능 향상을 제공할 수 있다.
하지만, unlabeled된 text에서 word-level 이상의 정보를 활용하기란 어렵다.
먼저, 어떤 최적화 함수가 transfer task에 효과적인 text representations을 학습하기에 적합한지 불확실하다.
두 번째, 학습한 representations를 target task에 맞게 어떻게 transfer하는게 가장 효과적인지 불확실하다.
이러한 불확실성으로 인해 language processing을 위한 효과적인 semi-supervised learning approaches를 찾기 어려웠다.
이 논문에서는, unsupervised pre-training과 supervised fine-tuning을 조합하여 language understanding tasks를 위한 semi-supervised approach를 탐색해본다. 이 연구의 목표는 광범위한 과제에 약간의 적응만으로 task에 맞게 변형시킬 수 있는 보편적인 표현(universal representation)을 학습하는 것이다.
3 Framework
훈련 과정은 두 단계로 이루워진다. 첫 단계는 거대한 text 자료를 가지고 대용량 언어 모델을 학습하는 것이다. 그 후 fine-tuning 단계에서 labeled data를 이용한 discriminative task에 모델을 적용시킨다.
3.1 Unsupervised pre-training
일반적인 언어 모델처럼 $k$개의 이전 토큰들이 주워졌을 때, 현재 토큰이 나올 확률을 구하는 likelihood 함수를 최대화하도록 한다.
| $L_1(U)=\sum_i log\ P(u_i | u_{i-k},…,u_{i-1};\Theta)$ |
여기서 $k$는 context window의 크기이고, 조건부확률 $P$는 parameters $\Theta$를 가지는 neural network를 이용하여 모델링된다. 그리고 이 parameters는 SGD(Stochastic Gradient Descent)를 통해 학습된다. 가령 $k$값이 4이면, 현재 우리가 예측하고자 하는 토큰 $u_i$ 이전 4개의 토큰 $u_{i-4}, u_{i-3}, u_{i-2}, u_{i-1}$가 주워졌을 때, 다음으로 $u_i$가 나올 확률을 최대화하도록 모델을 학습시킨다.
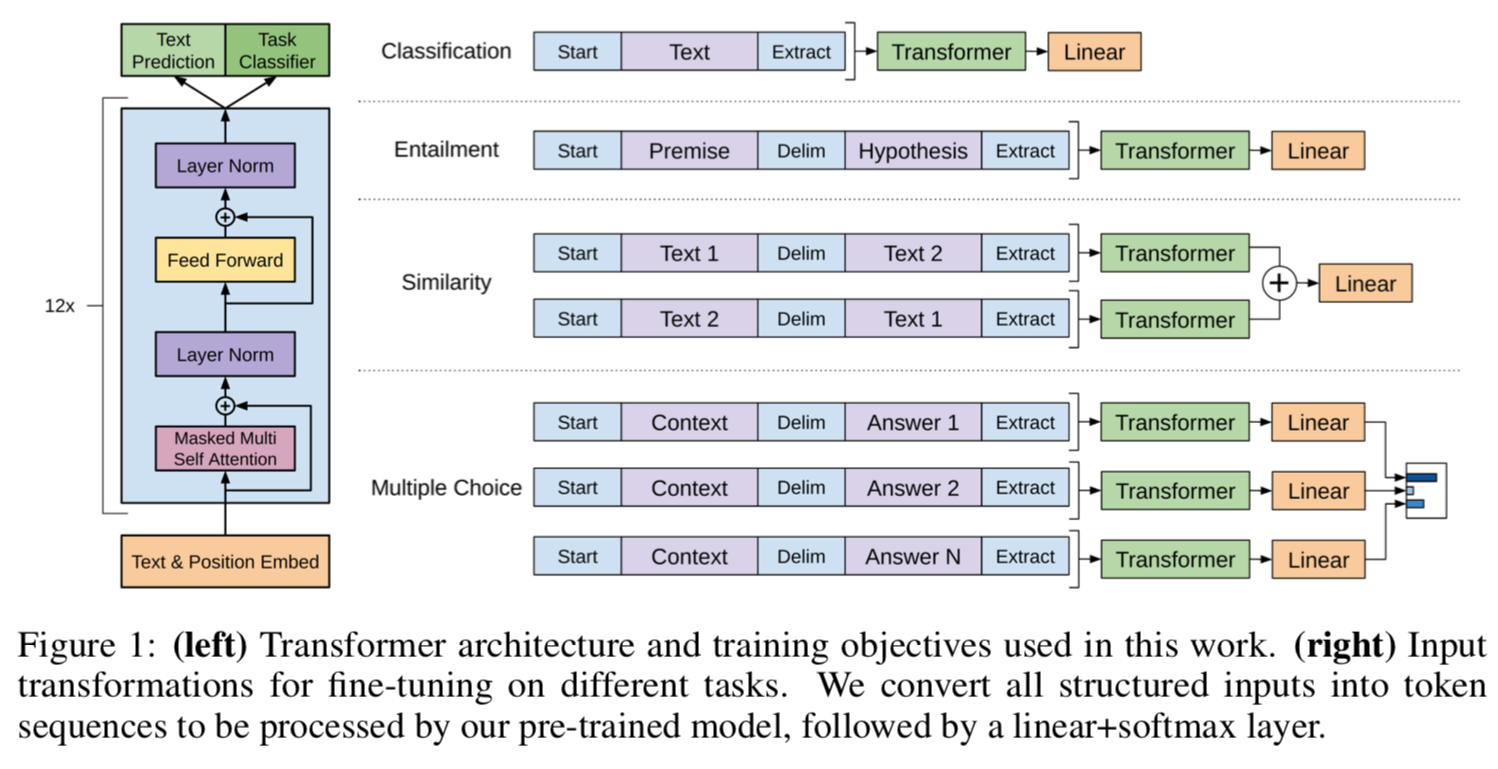
이 연구에서는 언어 모델로 multi-layer Transformer decoder를 사용했다.
Pre-training 과정은 이렇다.
$h_0=UW_e+Wp$
- input 토큰 U에 대해 token embedding과 position embedding을 수행해 $h_0$를 구한다.
$h_l=$ transformer_block$(h_{l-1})\forall i \in [1,n]$
- hidden state를 transformer block에 넣고 학습시키는 과정을 n개의 layer에 반복한다.
$P(u) =$ softmax$(h_nW_e^T)$
- 최종적으로 구한 hidden state를 이용해 확률을 구한다.
3.2 Supervised fine-tuning
언어 모델을 학습한 후, 모델의 parameters를 supervised target task에 맞게 조정한다.
토큰 $x^1,…,x^m$으로 이뤄진 문장과 우리가 구하고자 하는 label $y$가 있을 때, 먼저 input 데이터를 언어 모델에 넣어 최종 transformer 블록의 activation $h_l^m$을 구한다. 그 후 $W_y$를 parameters로 갖는 추가적인 linear output layer에 넣어 $y$를 예측한다.
| $P(y | x^1,…,x^m)=softmax(h_l^mW_y)$ |
그리고 다음과 같은 likelihood 함수를 maximize하도록 모델을 학습시킨다.
| $L_2(C)=\sum_{(x,y)}logP(y | x^1,…,x^m)$ |
이 연구에서는 추가적으로 언어 모델을 학습할 때 사용한 $L_1(U)$ 함수를 $L_2(C)$와 같이 사용하였더니, supervised model의 일반화를 개선할 수 있었고, 모델의 수렴을 가속화함을 발견했다.
따라서 $L_3(C)=L_2(C)+\lambda*L_1(c)$를 최대화하도록 fine-tuning 학습을 진행한다.
3.3 Task-specific input transformations
각 task에 맞게 input 구조를 다르게 하여 fine-tuning 학습을 진행한다.
- Classification : text 그대로 input으로 넣는다.
- Textual Entailment : premise(전제)와 hypothesis(가설)를 결합하고, 그 사이를 delimiter 토큰($)으로 구별하여 input으로 넣는다.
- Similarity : 유사도를 구할 두 문장을 겹합하고, 마찬가지로 delimiter 토큰으로 구별하여 input으로 넣는다. 문장 간의 유사도를 구할 때 내제된 ordering을 배제하기 위해, 두 문장의 순서를 바꿔 독립적으로 처리한다. 그 후 output을 softmax layer를 통해 정규화하여 가장 적절한 답변을 구한다.
- Question Answering and Commonsense Reasoning : context 문서 $z$와 question $q$를 가능한 가능한 답변 $\left{ a_k \right}$와 각각 결합하여 독립적으로 처리 후, softmax layer로 normalize하여 가능한 답변들에 대해 output distribution을 생성한다.
Conclusion
GPT는 unlabeled 데이터를 이용하여 unsupervised pre-training을 진행하고, 그 후 특정 task에 맞게 labeled 데이터를 이용하여 supervised fine-tuning을 진행하였고, 이를 통해 각각의 목적에 맞게 task를 수행할 수 있도록 만들어진 모델이다.
특정 과제에 적합한 모델 구조를 만들어내는 방식이 아닌, semi-supervised learning을 통해 Language Model을 학습시킨 후, fine-tuning을 통해 각 task를 수행할 수 있도록 모델을 학습시킨 점이 인상적이었다.
Leave a comment