
Language Models are Few-Shot Learners
Language Models are Few-Shot Learners
- Link: https://arxiv.org/abs/2005.14165
💡 핵심 아이디어가 뭐야?
NLP의 흐름이 과거에는 작업별로 표현을 학습하고 모델 구조를 설계했지만, 이제는 작업과 무관한 사전 학습과 구조 설계로 변화하였습니다. 하지만 여전히 최종 단계에서 작업에 맞는 미세 조정( Fine-Tuning)이 필요했습니다.
GPT-2는 이 미세 조정 없이 다양한 NLP 작업을 수행할 수 있는 zero-shot 학습을 보여주었으나, 성능은 baseline에도 미치지 못했습니다.
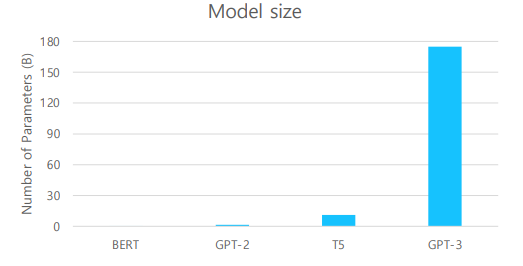
GPT-3에서는 모델의 크기를 10배 이상 키웠습니다. 그랬더니 few-shot 분야에서 좋은 성능을 보였습니다.
- zero-shot: 아무 예시도 없이 태스크 수행
- ont-shot: 하나의 예시를 보여주고 태스크 수행
- few-shot: 몇 개의 예시를 보여주고 태스크 수행
모델의 크기가 커질수록 더 뛰어난 few-shot 능력을 보인다고 하네요.
Leave a comment