
Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition
- Link : https://arxiv.org/abs/1512.03385
ResNet으로 더 유명한 논문
Residual 잔차
Neural Network에서 특정 layer를 통과한 input과 해당 layer의 output의 차이를 Residual(잔차)라고 한다.
Residual Learning(잔차 학습)은 이 차이, 즉 잔차를 학습하는 방식을 말한다.
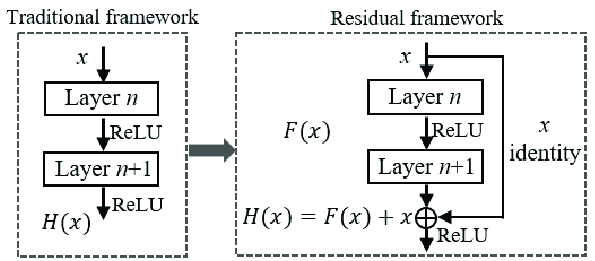
딥러닝에서 일반적으로는 layer를 통과한 input $x$ 에 대한 output $H(x)$ 를 얻습니다. Residual Learning에서는 이 output $H(x)$ 대신, input $x$ 와 $H(x)$ 사이의 Residual(잔차) $F(x)=H(x)−x$를 직접적으로 학습한다.
Residual Learning의 핵심 아이디어는, 만약 $H(x)$가 $x$ 와 매우 근접한 값이라면 $F(x)$ 는 거의 $0$에 가까울 것이다. 따라서, $H(x)$ 를 예측하는 대신 $F(x)$ 를 예측함으로써, network는 더 쉽게 학습될 수 있고(0이라는 숫자 개념으로 수렴하게 하는 것이 더 쉽기 때문), 이는 모델이 깊어질때 발생할 수 있는 에서 gradient vanishing problem을 완화시키고, 학습을 더 효율적으로 할 수 있게 한다.
“input과 동일한 값을 넘기도록 하는 것과의 차이는 뭐지?”
→ 단순히 input과 동일한 값을 넘기는 함수를 학습하는 것보다 $H(x)-x=0$을 목표로 하여 신경망의 학습 효율성을 높이고, 깊이가 길어질수록 발생할 수 있는 문제를 완화할 수 있다.
Bottleneck Block 병목 블록
Bottleneck block은 딥러닝 모델에서 메모리와 연산 비용을 줄이기 위해 사용되는 효율적인 구조이다. 주로 1x1, 3x3, 1x1 크기의 convolution layer를 순차적으로 쌓아서 구성하며, 주로 ResNet과 같은 deep neural network에서 사용된다.
다음과 같은 특징이 있다.
- Dimension Reduction : 1x1 convolution과 같은 작은 convolution layer를 사용하여 input data의 dimension을 줄여, 더 작은 차원에서 연산을 수행하고, 이에 따라 더 적은 parameter를 사용하게 하여 모델의 효율성을 높인다.
- Deep Block : 그 다음, 작은 차원에서 연산된 output을 deep convolution layer와 함께 처리하여, 더 복잡하고 추상화된 특징을 학습할 수 있다.
- Dimension Increase : 마지막으로 최종 ouptut dimension을 원래의 차원으로 복원하는 convolution layer를 사용하여 최종 output을 구한다.
Abstract
Deep Neural Network는 모델의 depth가 깊어질수록 학습하기 어렵다는 단점이 있다. 이를 위해 Deeper 모델을 쉽게 학습하기 위한 Residual Learning Framework 제안한다.
Residual network 이용하여 더 쉽게 optimize 하고, depth가 상당히 깊어짐에 따라 높은 정확도를 얻을 수 있다는 경험적인 증거를 보여준다.
VGG net보다 8배나 깊은 152개의 layers를 사용하면서 VGG net보다 복잡성이 낮고, ImageNet test set에서 더 낮은 error를 보여줌
Introduction
Deep CNN은 image classification에서 획기적인(breakthroughs) 성능을 보여줬는데, 모델이 깊어질 수록 좋은 성능을 보여줬다. 모델이 깊어질수록 vanishing/exploding gradients problem이 발생하는데, 이는 normalized initialization, intermediate normalization layers 등으로 어느정도 해결을 해왔다.
하지만, netwrok가 깊어질수록 accuracy가 떨어지는 Degradation Problem이 발생하는데, 이는 overfitting 문제와 달리 train accuracy와 test accuracy가 모두 떨어지는 현상을 보인다.(overfitting은 train accuracy는 올라가나, test accuracy가 떨어지는 형태임)
여기서는 layer가 더 깊이 쌓일수록 optimize가 복잡하기 때문에 생기는 문제라고 보고, shallow architecture(얕은 구조의 모델)과 deep architecutre를 비교해보려고 한다. 학습된 얕은 모델에 identity mapping(입력과 출력이 동일한 매핑 함수. 여기서는 skip connection을 통해 직접적으로 입력을 출력으로 전달하는 과정을 의미)을 추가하여 단순히 깊게 쌓는 deep architecture를 만들었지만 좋은 solution은 아니었다.
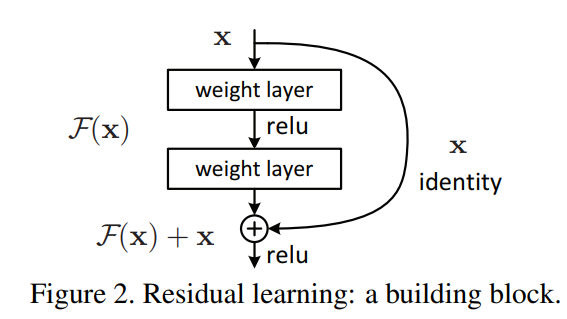
이 논문에서는 degradation problem을 해결하기 위해 deep residual learning framework를 제시한다. 이는 기존 mapping인 $H(x)$를 $F(x) := H(x)-x$ 즉, $H(x):=F(x)+x$로 mapping 하게 만든다. 이 residual mappingd 기존의 mapping보다 optimize하기 더 쉬운것으로 가정한다.
$F(x)+x$를 shortcut connection이라고도 말하는데, 이는 위 그림처럼 한 개 이상의 layer를 건너뛰기 때문이다. Shortcut connection의 또 다른 장점은 복잡한 계산을 skip한다는 것이다.
Deeper model 일수록 성능이 좋아지는 기존 연구와는 달리, 모델이 깊어질수록 발생하는 Degradtion problem을 해결하기 위해, residual learning을 도입한 Residual Network(ResNet)을 제안하여, 모델이 깊어져도 더 좋은 성능을 보였다. 50-layer 이상부터는 bottleneck block을 사용하여 계산량을 줄였다. 결과적으로, residual learning을 사용한 ResNet이 VGG를 바탕으로 만든 plain network보다 더 좋은 성능을 보였다.
Reference
https://velog.io/@jinhoyoho/논문-분석-Deep-Residual-Learning-for-Image-Recognition
Leave a comment