
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- Link : https://arxiv.org/abs/2010.11929
이 논문에서는 NLP에서 사용되는 Transformer를 이용하여 Image Classification을 수행할 수 있는 Vision Transformer 모델을 소개한다.
💡 Model Architecture
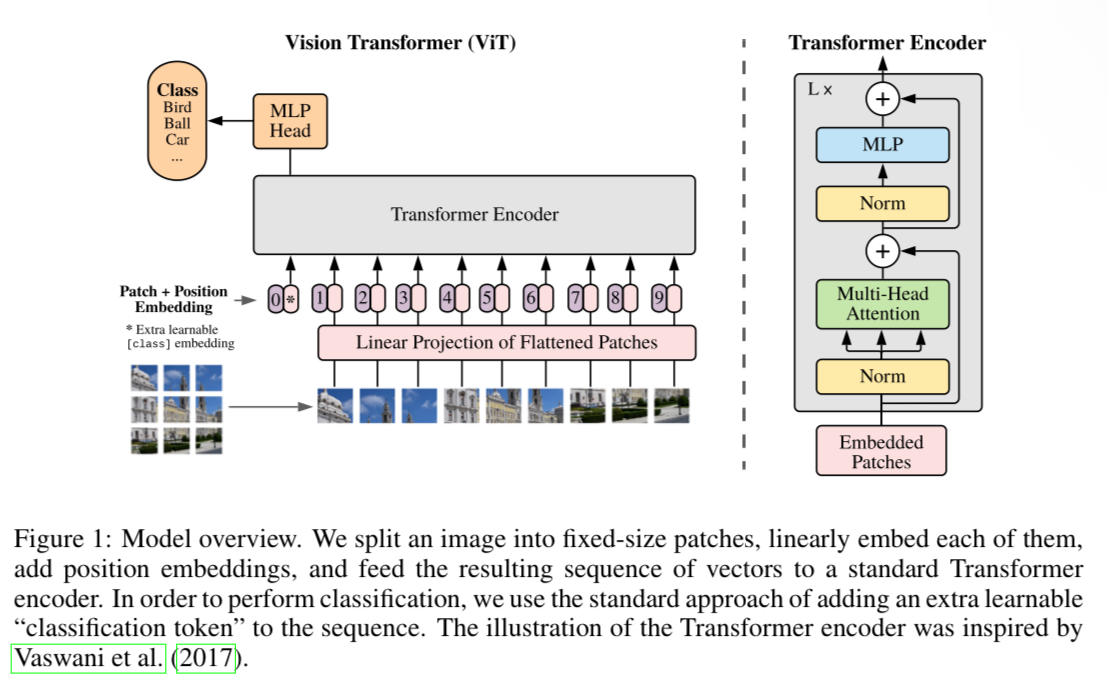
모델의 구조는 위와 같다.
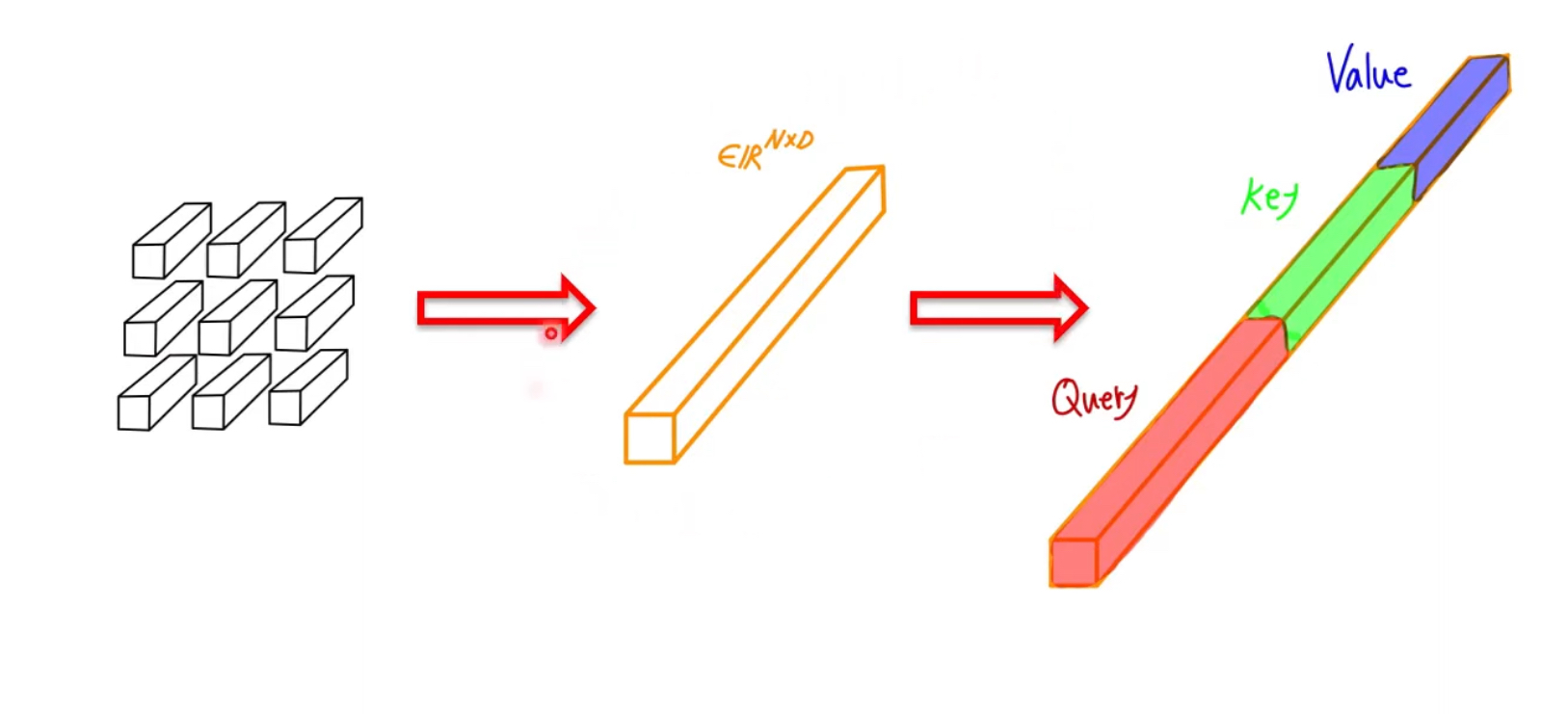
먼저 2D이미지를 1차원으로(Flattening) Embedding하기 위해, 이미지를 Patch단위로 쪼깨는 Patch Embedding을 수행한다.
Patch Embedding은 $x \in \mathbb{R}^{H \times W \times C}$ 이미지를 patch 단위로 쪼개어, 각 patch가 $x_p \in \mathbb{R}^{N\times (P^2 \cdot C)}$되도록 만들어준다.
- H: Height, W: Width, C: Channels
- $N=HW/P^2$
추가로, BERT에서 사용하는 [Class] 토큰과 비슷하게 Input Embedding의 맨 앞에 [Class] Patch를 넣어준다. [Class] 패치는 Transformer Encoder의 출력($z_l$ )의 맨 앞($z_l^0$)에 대응되며 이후 MLP의 input으로 들어가 classification에 사용된다.
또한 각 patch들의 순서정보를 넣어주기 위해 Positional Encoding을 각 Patch Embedding에 더해준다.
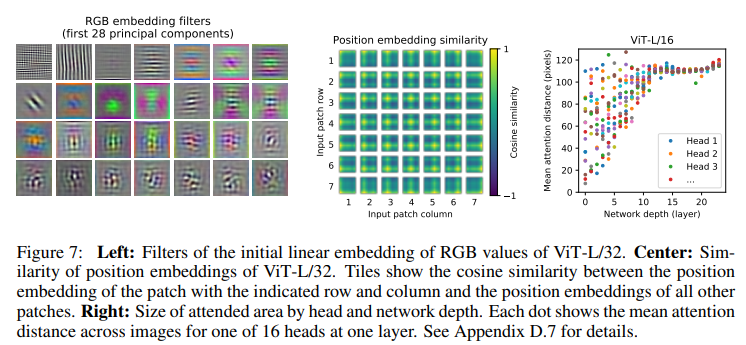
Positional Encoding은 위 사진 중 가운데의 모습처럼, 자신의 patch가 가장 활성화되어있는 모습을 볼 수 있다.( (1,1) patch는 왼쪽 맨위 모서리가 가장 활성화 되어있음) 이와 같은 positional encoding을 patch embedding에 더해줘 위치값을 보존할 수 있다.
이렇게 구해진 벡터를 Transformer Encoder의 input으로 넣어주고, Transformer Encoder로부터 출력한 Output을 MLP의 input으로 넣어 image classification을 수행한다.
이때, 여기서 사용한 Transformer Encoder는 기존의 Transformer의 Encoder와는 구조가 조금 다르다.
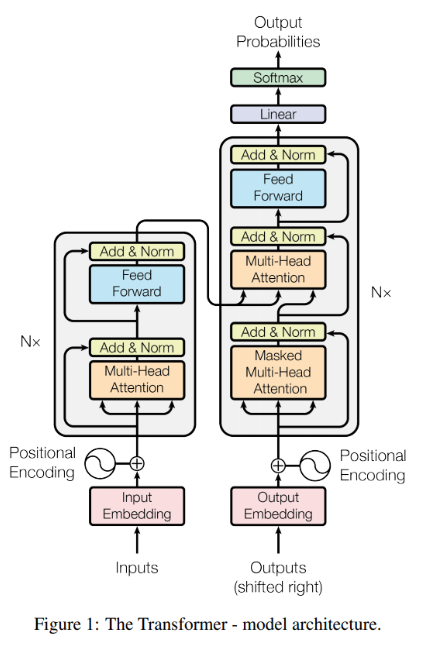
Transforemr - Attention Is All You Need
여기서 사용한 Transformer Encoder는 Normalization을 먼저 수행해주는 것을 볼 수 있다.
위 모델의 구조를 수식으로 표현하면 다음과 같다.
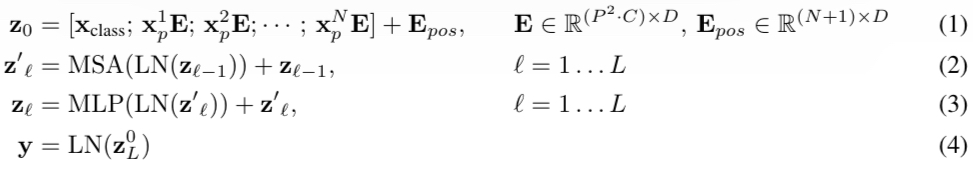
ViT를 수식으로 표현
- MSA: Multi-Head Self-Attention
- LN: Layer-Normalization
- $Z’l, Z_l$에서 residual connection($+z{l-1},z’_l$) 사용
💡 Hybrid Architecture
이미지를 Patch단위로 쪼개어 Linear Projection을 통해 Embedding Vector로 만드는 대신에, CNN을 이용하여 구한 Feature Map을 Transformer의 input vector으로 넣어 사용할 수도 있다.
💡 Result

각 이미지의 적절한 부분이 활성화된 모습을 볼 수 있다.
💡 Self-Supervision
BERT에서 self-supervised pre-training을 한 것처럼, ViT에서도 Patch의 일부를 masking하는 방식으로 성능을 향상 시키려는 시도를 했다.
Leave a comment